|
|
You are here: Foswiki>Applications Web>AppOnCallDutyMain (01 Feb 2024, AnnekeWalter)Edit Attach
On-call duty / Rufbereitschaft - Main Page
These pages collect necessary information for on-call duty. Relevant information about system access, location of log files, restart/reboot operations and support for specific applications is all collected or linked here.- 0. General information
- 1. System access
- 1.1 For Development: Via Citrix to the Development Cluster (works fine)
- 1.2 For Development: Remote Desktop to the Development Cluster (works fine)
- 1.2.1 from Windows
- 1.2.2 from Linux
- 1.3 For general purposes: Remote Desktop to your GSI Windows computer (works fine)
- 1.4 Working locally using linux based host OS
- 1.5 HowTo mount the windows file share on the asl7xx cluster
- 1.6 HowTo access the old Acc6 Cluster
- 2. Misc
- 3 Applikationen
- 4. Zusammenarbeit mit Timing-Rufbereitschaft
- 9. LSA
- 12. APP Dienste / Services
- 13. RemoteLauncher service
- 14. HF-Service-App (expert-hf-app)
- 15. HowTo
- Weiteres
0. General information
Handout Rufbereitschaft
How-To: Arbeitszeiten und Rufbereitschaft
Duties additionally to actual on-call duty
- Visit HKR once or twice a day and ask for issues. Spend more time there in case of problems.
- Monitor OLOG entries
- Shift and technical defects (Shift and Cone icon)
- Visit the "Morning Briefing" (8.30Uhr, Zoom) and be ready to report about APP OLOG entries. In case you cannot participate, organize an APP colleague that can attend instead.
- Visit the "Mittagssitzung" (12:45Uhr, Zoom) and be ready to report about APP OLOG entries. In case you cannot participate, organize an APP colleague that can attend instead.
- Visit "OCM Meeting" on Wednesdays (9:00Uhr, Kühlschrank) if neither JF nor AW is going, be ready to report on issues listed in the Technical Defect Report (OLog Login required).
(If nobody is there/ has time, talk to Regine Pfeil or HH and report in detail about APP issues so that they can report on the status instead)
"Who you gonna call?" poster
 Sources: odp, graphml
Sources: odp, graphml
Contacts
- HKR phone numbers
- FRS Messhütte: Tel.
-2862
1. System access
1.1 For Development: Via Citrix to the Development Cluster (works fine)
Citrix: Use your computer at home and with the Citrix client Software to access GSI. To enable Citrix access follow these instructions. From the Terminal Server to which you logon, you then use Remote Desktop to connect to the Linux Cluster atasl751.acc.gsi.de using your acc-Account.
1.2 For Development: Remote Desktop to the Development Cluster (works fine)
To connect to the Development Cluster, you can connect with a remote desktop toasl751.acc.gsi.de:3389 (default RDP port).
1.2.1 from Windows
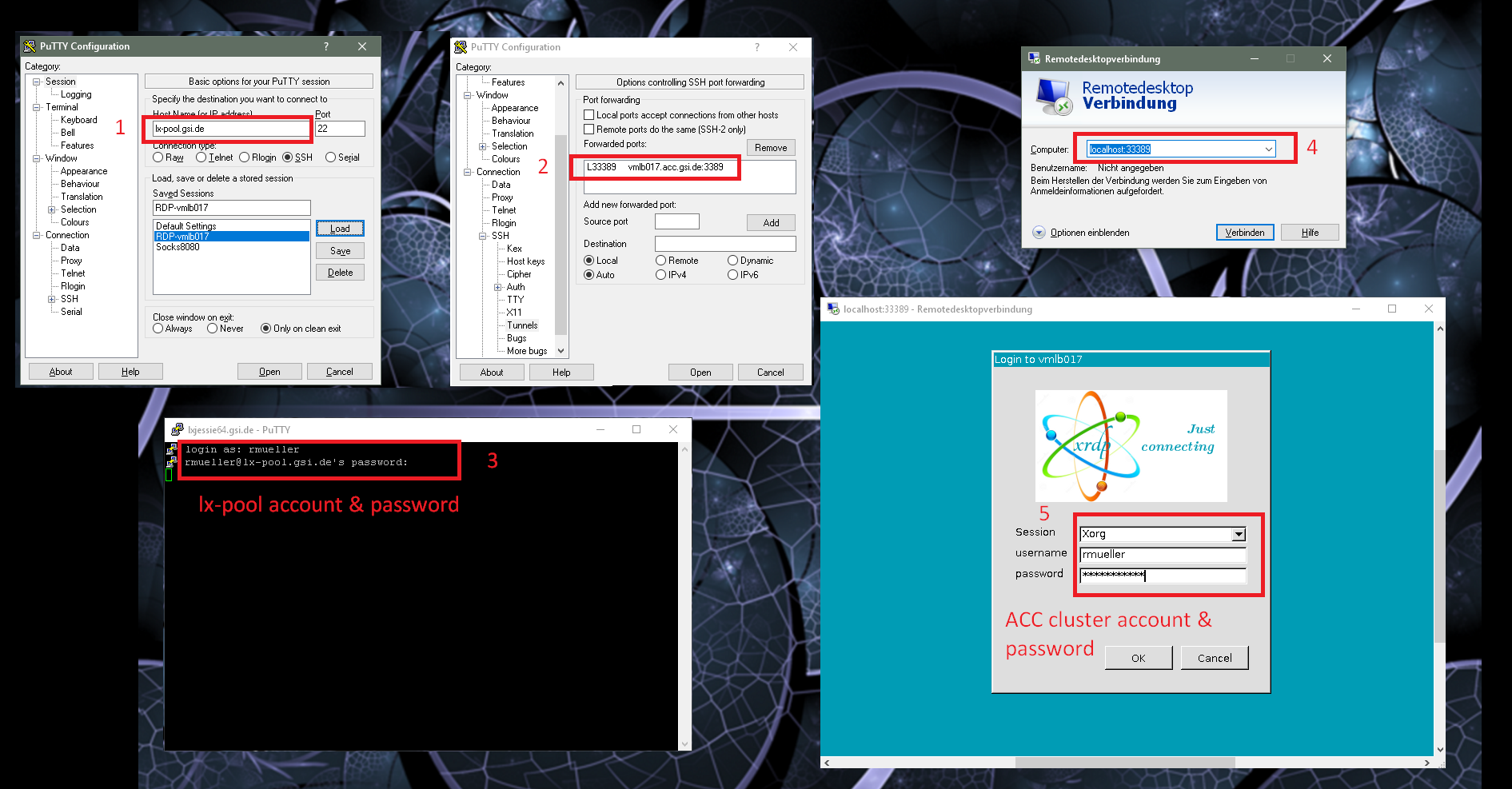
An example of my configuration for connecting is shown here (it still shows the old test VM, change thevmlb017 address to asl751, also instead of lx-pool.gsi.de, you can use the slightly faster lxlogin.gsi.de):
Screenshot of Windows Putty and Remotedesktop configuration
The Central IT also has a detailed explanation that can be consulted:
SSH-Tunnel für Remote-Zugriff auf GSI-Windows-Geräte.
1.2.2 from Linux
Tunnel must have been set up before using port forward or sshuttle. Minimal example:rdesktop -g 100% asl751.acc.gsi.de:3389With some tweaks:
rdesktop -p - -g 2560x1440 -D -N -r clipboard:PRIMARYCLIPBOARD asl751.acc.gsi.de:3389
-p -: Prompt for password on shell, skips login screen, allows copy/paste
-g : Define screen geometry
-D : Do not use window decorations
-N : Sync Num-Lock state
-r clipboard : Make clipboard work better
1.3 For general purposes: Remote Desktop to your GSI Windows computer (works fine)
To get to your own machine throughlx-login or lx-pool, you can use a ssh tunnel. On MacOS or Linux, entering the following command on the command line:
ssh -L 54321:belpc123.campus.gsi.de:3389 lxlogin.gsi.dewhere
54321 is an arbritrary local port, and belpcxxx is your machines hostname. On Windows, Putty provides similar functionality (and probably other tools as well).
Then, you can run a remote desktop client directly from the machine where you opened the tunnel. Be sure to specify the locally mapped port (54321 in the example above) as the one to connect to. From a windows environment, you can use Remote Desktop, from a Linux environment rdesktop. To enable remote desktop access follow these instruction
1.4 Working locally using linux based host OS
To work on a local machine one can tunnel all services through lx-login using ssh. The script provided by Andreas simplifies the needed steps. However, when starting applications this might become a bit slow compared to remote desktop sessions since more context information need to be downloaded to the local host.1.5 HowTo mount the windows file share on the asl7xx cluster
See AppOnCallDutyWindowsShareOnCluster.1.6 HowTo access the old Acc6 Cluster
For registered users (currently only Jutta in our group), access to the oldAcc6 cluster is still possible for maintenance purposes. See AppOnCallDutySystemAccessAcc6.
2. Misc
2.1 Tools
For readout of FESA devices, the FESA Explorer can be used. It is available in the launcher tab "Miscellaneous" under "Expert Apps". For more information about the usage, see here. The Prophelper for readout of Device Access devices can be started from the launcher tab "Development". Remember to select the virtual accelerator, which corresponds with the sequence number (at least 2018). Also remember to click "Show properties" (hitting "Enter" doesn't work reliably anymore as of 2023-09). For more information about the usage, see here. Tool to show FESA device information:/common/usr/cscofe/bin/pdex GS12MU3I Setting -s p3Tool to show LSA context information:
# on the dev cluster asl4xx - shows pro information /common/usr/cscoap/bin/lsa_residump [-t]Alternatively open: https://lsapro00a.acc.gsi.de/lsa/client/v2/status
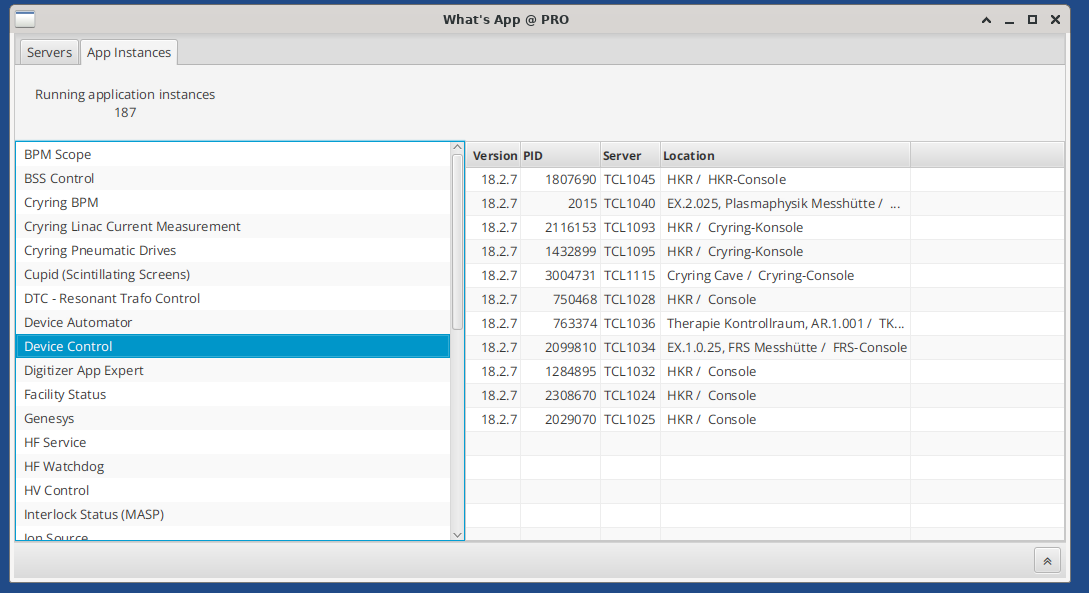
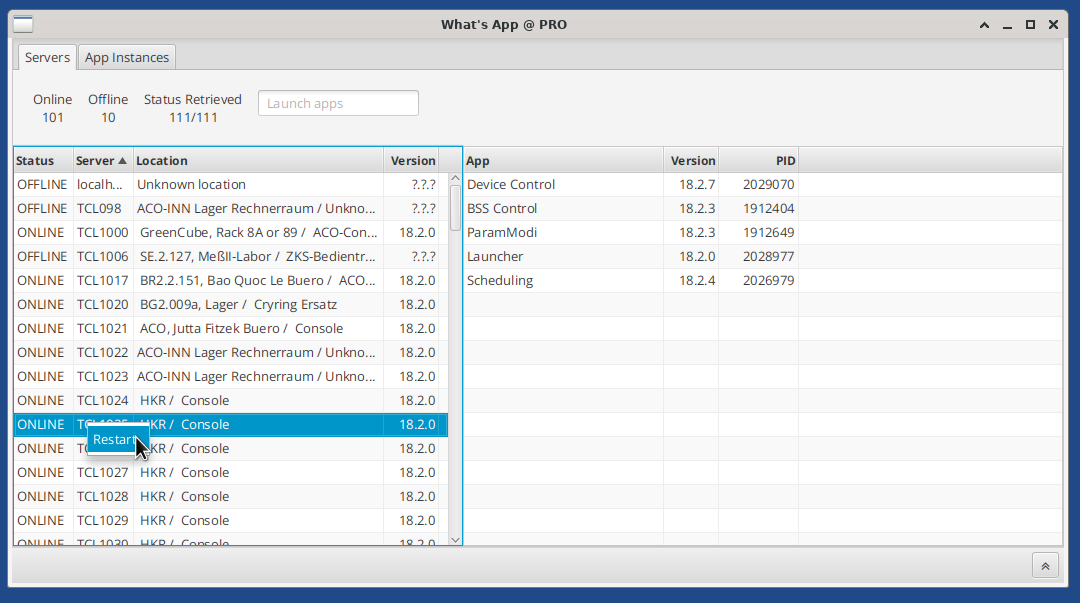
2.2 What's App
Manage running webstart application across the facility. See tcl locations.Servers view
Observe apps running on a tcl. See information about RemoteLauncher status and version and tcl location. Launch apps: Select a tcl and enter an app name in the text field 'Launch apps". Restart tcl: Select a tcl and click on the context menu item: "Restart". Please note that there is no automatic reconnect currently (2023-10-11). Please restart the app when you are done restrating tcls. Restart/quit app instance: Select an app instance and right-click to open the context menu.
App instances view
See all instances of an app across the facility. Watch out for outdated app instances. Restart/quit all instances of an app: Right-click on an app to open the context menu. Restart/quit app instance: Select an app instance and right-click to open the context menu.
3 Applikationen
3.1 DeviceControl
See AppOnCallDutyDeviceControlApp.3.2 SchedulingApp
See AppOnCallDutyInfoSchedulingApp.3.3 BSS Control
- Setzen von RepetitionCounts für Patterns
- Signale setzen, die Ausführbarkeit von Patterns steuern
3.3.1 Tipps im Fehlerfall
- Information für MASP ist unknown (grau): Logging-System prüfen, ob Probleme mit Subscription vorliegen. Prüfen, ob MASP läuft (z.B. MASP-Gui / Interlock-Programm). Wenn der Verdacht besteht, dass der MASP nicht läuft/keine korrekten Daten liefert etc.: Frontend-RB. (Experte: T. Habermann)
- Informationen für Signals sind unknown (grau): Logging-System prüfen, ob Zugriff auf RequestProcessor -REST-API funktioniert. Wenn der Verdacht besteht, dass der RP nicht läuft/keine korrekten Daten liefert etc.: BSS-RB (Services)
3.4 RequesterApp
- Anforderung von Strahlzielen: Daueranforderung (jede Ausführung, die möglich ist), Einmalanforderung (genau einmal ausführen (unter Berücksichtigung des Repetition Counts!)), Anforderung zurücknehmen/abbrechen
3.4.1 Konfiguration von Strahlzielen
Im Config-File der RequesterApp für dev/int/pro wird konfiguriert, welches Strahlziel auf bestimmten Rechnern/Konsolen angefordert werden kann:requester.host_[rechnerbezeichnung]=[Strahlziel] requester.host_tcl1041=HADES requester.host_asl744.acc.gsi.de=HTPAchtung: HKR- und Experiment-Konsolen ohne
.acc.gsi.de, ASL-Maschinen mit .acc.gsi.de!
Achtung: Dumps (z.B. HHD) sind implizit immer angefordert, sie sind nicht an-/abforderbar. Es ergibt daher keinen Sinn, sie auf Rechnern als Strahlziel zuzuordnen.
Eine erfolgreiche Zuordnung erkennt man daran, dass die RequesterApp unter "Strahlanforderung" gut sichtbar das jeweilige Strahlziel (z.B. HTP) und mehrere Buttons für die Anforderung anzeigt, wenn sie auf einem bestimmten Rechner gestartet wird. Fehlt im Config-File die Zuordnung für einen bestimmten Rechner, so fehlt in der Anwendung, wenn sie auf dem betreffenden Rechner gestartet wird, sowohl die Anzeige des Strahlziels als auch die Buttons. In der Anwendungskonsole sollte eine entsprechende Fehlermeldung erscheinen, z.B. "Für Konsole [Rechnerbezeichnung] wurde kein zugeordnetes Strahlziel gefunden, fehlende Konfiguration." o.Ä..
3.5 ParamModi
See AppOnCallDutyInfoParamModi.3.6 Storage Ring Mode App
AKA StoRiMo See AppOnCallDutyInfoStoRiMo.3.7 Digitizer App
See AppOnCallDutyInfoDigitizerApp3.8 Altes Quellenprogramm "IQ Program"
Beim Fortran-Quellenprogramm und auch insb. beim Hintergrunddienst zum Wegschreiben der Messdaten ".dat-Files" kann es vorkommen, dass das IQ Program hängt und/oder keine .dat-Files geschrieben werden. Typischerweise liegt es daran, dass keine VME Rahmen erreichbar sind bei entweder einer der drei Unilac Quellen oder ihrer zugehörigen Teststände. Der Fortran Code erwartet, dass alle erreichbar sind! Auch wenn nicht überall Betrieb gemacht wird. Man kann diese Situation leicht prüfen, indem man in der neuen ionsource-app alle Unilac Terminals durchklickt. Sind die Geräte erreichbar, aber aus, ist alles ok. Bekommt man in der neuen App für ein Terminal timeout-exceptions und sie die Geräte gar nicht erreichbar, muss man den entsprechenden Quellenkollegen Bescheid geben, dass die FrontEnd Rechner eingeschaltet werden (nur sie kommen dort hin). Wenn alle Geräte wieder erreichbar sind, muss der iqwrite-Prozess durch Susi neu gestartet werden.3.9 Neues Quellenprogramm "ionsource-app-fx"
Da die alten Front-Ends nur eine begrenzte Zahl an verbundenen Clients erlauben (schätzungsweise 10, es gibt jedoch keine fixe bekannte Zahl), sieht der nächste Nutzer, der die IonSource App öffnet, beim Verbindungsaufbau zu den Geräten von vielen den Fehler "too many subscriptions" bzw. "number of connections exceeded". Dann mit Hilfe von "What's App" und in Absprache mit dem HKR überzählige ionsource-app-fx Instanzen schließen. (Das Problem ist terminalbezogen. Instanzen im Cryring Kontrollraum oder an der Cryring Console können entsprechend weiterlaufen.) Um zu prüfen, wie viele Instanzen pro Terminal laufen (auf TCLs und auf dem Cluster), gibt es seit ionsource-app-fx 18.2.13 einen Mechanismus, der regelmäßig im Logging-System meldet, welches Terminal gerade geöffnet ist. Nicht berücksichtigt werden Instanzen, die nicht ins Logging loggen. Typischerweise sind das aus dem Workspace gestartete Instanzen - es sei denn, man hat eine entsprechend konfigurierte log4j-Config explizit angegeben. Instanz-Terminal-Logging einsehen:- Logging-System aufrufen
- Stand 2023-11:
- Nicht einloggen, sondern User
opendistro_security_anonymousverwenden. Tenant: private - Discover
- Gespeicherte Suchen öffnen via Open:
AW: IonSrc Selected Terminal Logging(ggf. suchen oder Seiten durchklicken) - Tipps zur Interpretation (falls nicht selbsterklärend)
- Gespeicherte Suchen öffnen via Open:
- Nicht einloggen, sondern User
3.10 Profilegrid App
See AppOnCallDutyInfoProfilegridApp4. Zusammenarbeit mit Timing-Rufbereitschaft
CS-Panic darf jederzeit in Absprache mit dem HKR benutzt werden.Sollte vor der Benutzung ein Problem mit dem Timing (Datamaster) bestanden haben, ist die Timing-Gruppe zwecks Fehlerfindung zu informieren (nicht zwingend die RB).
4.1. Probleme mit BSS und Timing
Bugs in BSS, Data Master, und der Kommunikation zwischen diesen Komponenten bzw. zwischen LSA und diesen Komponenten können dazu führen, dass sich das gesamte System "verklemmt". Das äußert sich z.B. darin, dass das System nicht mehr reagiert (Fehlermeldungen beim Ein- und Ausplanen von Patterns, beim Deaktivieren von Patterns, usw.) oder inkonsistent ist (z.B. scheint ein Pattern gemäß der Infos im BSS Control nicht ausführungsfähig zu sein, an den Events im Snoop Tool erkennt man jedoch, dass es läuft) usw.4.1.1 Bekannte Ursachen
4.1.1.1 LZMA Decompression Exception / Input Stream Error (Februar 2019)
Der Timing Master wirft u.U. eine Exception, wenn mehrfach hintereinander die gleiche Aktion auf den gleichen Daten ausgeführt wurde. Dies erkennt man daran, dass es im Logging-System Exceptions z.B. aus der Scheduling App, BSS Control, dem Request Processor, etc. gibt, die als Cause "Decompression: LZMA reported ERROR DATA" beinhalten. Die Behandlung erfolgt durch einen Reset des BSS in Zusammenarbeit mit der Timing-RB. Beispiel:11 Feb 2019 15:02:00,510 Fehler beim Aktualisieren der PatternGroups java.lang.RuntimeException: An error occurred while trying to execute the 'dump' command on the Generator. See diagnostic logging for more information. at de.gsi.cs.co.lsa.bss.GeneratorAdapter.executeDumpCommand(GeneratorAdapter.java:261) ... <b>Caused by:</b> cern.japc.ParameterException: Decompression:<b> LZMA reported ERROR DATA (1)</b> ... <b>Caused by:</b> cern.cmw.rda3.common.exception.ServerException: Decompression:<b> LZMA reported ERROR DATA (1)</b> ...Wenn bereits beim Schreiben ein Fehler aufgetreten ist, dann sieht die Meldung etwas anders aus. Die Behandlung ist identisch.
A-Priori Verify for LZMA compression failed, Decompression:<b> LZMA reported ERROR DATA </b>(1)Am 01.03. wurde die LZMA Library ausgebaut. Am 04.03. trat ein höchstwahrscheinlich verwandter Fehler mit dem Exception-Text "input stream error" auf:
cern.japc.ParameterException: *input stream error* at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
...
<b> Caused by:</b>
cern.cmw.rda3.common.exception.ServerException:<b> input stream error</b> at cern.cmw.rda3.common.util.ExceptionUtils.createRdaServerException(ExceptionUtils.java:75)
...
Es wird vermutet, dass dieser Fehler die eigentliche Ursache ist und auch bereits der Auslöser für die LZMA Exceptions war. Solange die LZMA Library ausgebaut ist, wird statt LZMA Exceptions ggf. dieser Fehler in Logs angezeigt. Die Behandlung ist identisch.
8.1.1.2 "Outdated Context" exception
Kann dazu führen, dass gesamte PatternGroup steht, da "disabled by LSA" Signal gesetzt ist, nachdem Drive fehlgeschlagen ist, weil der mitgesendete Kontext veraltet war (z.B. veraltete Längen, veraltete User/Selektoren, etc.). Vermeidung: Regelmäßiges Refreshen von Anwendungen, explizites Refreshen nach Kontrollsystem-Reset. Behebung: Erfolgreiche Versorgung eines Patterns aus der PatternGroup über LSA, z.B. Vollversorgung/Drive aus neugestartetem oder per (Client-)Refresh aktualisiertem ParamModi.8.1.2 Fehlerbehebung
Vorher: Kontakt zu Services-Rufbereitschaft bzgl. BSS und zu Timing-Rufbereitschaft bzgl. Generator/Data Master. Problem besprechen.Per Tool
Der Reset kann durch das Tool expert-cs-panic-app (ACO-APP Expertenprogramm) durchgeführt werden.Manuell
Falls Reset durchgeführt werden soll:- Ist-Zustand dokumentieren, um ihn später wiederherstellen zu können (eingeplante Patterns, Unilacanforderungen, gekoppelte Patterns, aktivierte Patterns/Pattern Groups - z.B. Screenshots von Scheduling App oder BSS Control, inkl. Koppel-Dialog im BSS Control).
- Im BSS Control z.B. per "Pattern deaktivieren" ALLE Patterns deaktivieren. (Hintergrund: Es könnte sonst sein, dass nach dem Wiedereinplanen einzelne Patterns SOFORT loslaufen, falls das BSS noch veraltete Signal-Infos hat!)
- Reset-Vorgang:
- Falls gekoppelte Patterns vorhanden: BSS Control aus aktuellen Release-Branch auschecken. BSS Control aus dem Workspace starten mit den unten angegebenen VM-Parametern und dem Profil pro-2tier. Oben rechts "Patterns koppeln" anwählen und alle entkoppeln.
- Scheduling App aus aktuellen Release-Branch auschecken. Scheduling App aus dem Workspace starten mit den unten angegebenen VM-Parametern und dem Profil pro-2tier. Alle Patterns ausplanen (aus Pattern Groups entfernen und oben rechts Supply/Versorgen klicken).
- [Parallel: Timing-RB setzt Generator/Data Master zurück, evtl.: Services-RB setzt BSS zurück.]
- Wenn Schritt 3 vollständig erledigt (auch von anderen RBs):
- Scheduling App aus dem Pro-Launcher starten. Dort alle gewünschten Patterns wieder einplanen* und oben rechts Supply/Versorgen klicken.
- Beim Einplanen ist ggf. zu berücksichtigen, dass bestimmte laufende Experimente z.B. ihren Virtuellen Beschleuniger für den SIS18 (S... im ContextWidget) behalten wollen. Dies kann über die Einplanungsreihenfolge gesteuert werden (es wird immer der nächste freie Virtuelle Beschleuniger genommen). Ggf. beim HKR nachfragen. Notfalls alle Patterns einzeln nacheinander einplanen, in der Reihenfolge der angegeben Virtuellen Beschleuniger für SIS (S..) und ESR (E..) (beide nutzen den gleichen Zahlenraum).
- BSS Control aus dem Pro-Launcher starten. Dort Kopplungen wiederherstellen. Ggf. in Schritt 2 deaktivierte Patterns wieder aktivieren.
- Scheduling App aus dem Pro-Launcher starten. Dort alle gewünschten Patterns wieder einplanen* und oben rechts Supply/Versorgen klicken.
- Client-Refresh in allen offenen ParamModi-Anwendungen (sonst steht LSA evtl. nach nächster Versorgung! siehe OutdatedContextException), am besten auch SchedulingApps neustarten.
-Dcsco.default.property.config.url=http://config.development.lb.a.k8s.acc.gsi.de/application/profile/dev/ -Dlsa.bss.generator.dataSupplyEnabled=false -Dlsa.bss.director.dataSupplyEnabled=false -Dlsa.bss.requestProcessor.dataSupplyEnabled=falseDie Programme können auch entsprechend per command line gestartet werden:
mvn clean compile exec:java -Ppro-2tier -Dlsa.bss.generator.dataSupplyEnabled=false -Dlsa.bss.director.dataSupplyEnabled=false -Dlsa.bss.requestProcessor.dataSupplyEnabled=false
9. LSA
Fehler aus LSA können verschiedene Ursachen haben:- Model (David & Co.)
- Fehlermeldungen wie "out of limits"
- Netzwerk
- Fehlermeldungen wie "Port unreachable" / "Can not (de)serialize" (REST)
- Anwendung neustarten
- prüfen ob LSA-Server läuft (auf
asl151)[user@asl151 ~]$ sudo -u bob bash [bob@asl151 lnx]$ systemctl --user status lsa-server-gsi
- Abhängigkeiten (Versionen von LSA) überprüfen
- entweder unter About in der Anwendung (falls verfügbar) oder im
pom.xmlder releasten Anwendung
- entweder unter About in der Anwendung (falls verfügbar) oder im
- Server Neustart (falls nötig)
[user@asl151 ~]$ sudo -u bob bash [bob@asl151 lnx]$ systemctl --user restart lsa-server-gsi
- Fehlermeldungen wie "Port unreachable" / "Can not (de)serialize" (REST)
- Performance Probleme
- Datenbank auf hängende Jobs überprüfen (evtl INN Rufbereitschaft)
- BSS
- Signale überprüfen
- Neustart (wenn nötig) über SV Rufbereitschaft
- anschließend Vollversorgung aus Scheduling App
- MASP überprüfen
- Beam Modes korrekt gesetzt? (in ParamModi suchen nach
beam_mode) - Neustart (wenn nötig) über FE Rufbereitschaft
- anschließend Vollversorgung aus Scheduling App
- Beam Modes korrekt gesetzt? (in ParamModi suchen nach
- Patterns aus und wieder einplanen
- DM status über FESA-Explorer (
cmwpro00a → tsl017)
- DM status über FESA-Explorer (
9.0. LSA Server Release
Folgende Projekte sind zu releasen:-
lsa-ext-fair-gsi -
lsa-server-gsi
lsa-ext-fair-gsi geändert (Modell, Berechnungen). Einfache Bugs (z.B. Javadoc-Bugs, ggf. auskommentieren) fixen. Wie folgt vorgehen: - pull von
lsa-server-gsiundlsa-ext-fair-gsi -
lsa-ext-fair-gsi:mvn release:prepare release:perform - uU. java docs fixen oder kommunizieren
-
lsa-server-gsi:lsa-ext-fair-gsiAbhängigkeit hochzählen -
lsa-server-gsi: release (s.o.) - Info an HKR: keine Eingaben möglich, keine Trims machen während Deployment
-
lsa-server-gsi: rollout (beinhaltet neustart) über ansible Rollout of Services and Applications - Info an HKR: wieder ok
-
lsa-ext-fair-gsi → lsa-server-gsi → parammodi-appSNAPSHOTAbhängigkeiten eintragen -
lsa.mode=2und pro Konfig - Dann kann man die make rules debuggen
- Debugger nicht unnötig im Breakpoint stehen lassen da trim lock solange besteht!
In der Regel durch: AS, RM, HH
eigentlich nie in der RB, sollte auch nur durchgeführt werden, wenn man sich damit auskennt!
Evtl.
- LSA Server stoppen
-
lsa-db-scripts,expert-db-config-tool - LSA Server starten
9.0.1 Hierarchie-/Parameteränderungen
Änderungen an der Hierarchie oder bei Parametern werden idR. tagsüber gemacht! Dazu ist ebenfalls die direkte Absprache mit dem HKR erforderlich oder es wird ein Wartungsfenster benötigt. Dafür auch dascommon-lsa-utils-uilib Projekt auschecken. Hier werden ggf. neue Oberflächentexte hinzugefügt, die z.B. im ParamModi angezeigt werden.Die Modellierer müssen angeben, welche Applikation(en) neu released werden müssen (ParamModi, SchedulingApp).
Mit dem HKR ist immer abzustimmen, wenn die Applikationen neu ausgerollt werden: Vor dem Neustart müssen die alten Applikations-Instanzen vorher beendet werden. Ansonsten können Inkonsistenzen auftreten!
9.1. BP_DELETION_ERROR : Failed delete_beamprocess_action
Sollte es beim Versuch, Kontexte zu Löschen, zu Fehlern der folgenden Art kommen:BP_DELETION_ERROR : Failed delete_beamprocess_action with bp id 73730, Err: ORA-00001: unique constraint (LSA.BP_NAME_UK) violated ORA-06512: at "LSA.SETTINGS_MANAGEMENT", line 1504So liegt das daran, dass in diesem Kontext ein Beam Prozess enthalten ist, der den gleichen Namen trägt, wie ein anderer Beam Prozess, der am gleichen Tag gelöscht wurde. (Beispiel: Es wurde ein Pattern "ABC" erstellt, gelöscht, ein neues Pattern "ABC" erstellt, gelöscht -> gelöschte Beam Prozesse tragen gleichen Namen). Da Beam Prozesse nicht sofort gelöscht werden, sondern zunächst nur als zu löschend markiert werden, kommt es zu einer Constraint-Verletzung wegen des gleichen Namens. Das sollte normalerweise kein Problem sein, da dem Namen eine Nummer angehängt wird, die hochgezählt wird. Allerdings kann es in seltenen Fällen, wenn sehr viel gelöscht wird, dazu kommen, dass die Nummer überläuft, und dann kommt es doch zu gleichen Namen und Fehlern. Lösungen:
- kurzfristig: Eventuell reicht, es einfach nochmal zu probieren. Ansonsten zu löschenden Kontext umbenennen und dann löschen. (Vermutlich ausreichend gute Lösung für einen RB-Einsatz!)
- sauberer: Services-RB rufen und darum bitten, dass der Job zum Löschen der "gelöschten" Beam Prozesse händisch angestoßen wird. (Vermutlich während RB nicht unbedingt notwendig. Der Job läuft normalerweise täglich gegen 8:00 Uhr.)
12. APP Dienste / Services
- Existierende Dienste, URLs, Ports und deren Konfigurationen: ApServiceLocationDefinitions
- Pro Dienste werden von systemd verwaltet und laufen als Benutzer
bobaufasl156.acc.gsi.de- Eine Dokumentation des setups und der wichtigsten Befehle von INN: https://git.acc.gsi.de/handel/bob-services/src/branch/master/bob.md#systemd
- Rollout von Diensten mit Ansible, Neustart sollte dann automatisch erfolgen!
- DEV-Dienste (nicht RB-relevant, aber der Vollständigkeit halber): Siehe Applications/AppHowToContainer.
13. RemoteLauncher service
Der RemoteLauncher -Service läuft auf jeder Konsole, Dort wird er bei jedem Start der Konsole mitgestartet. Falls der Dienst nicht mehr über WhatsApp neugestartet werden kann, so muss er beendet werden, um ihn automatisch neu zu starten (Der Typo launcer ist Absicht!):systemctl --user restart app-cscoap-remotelauncerAchtung, alle durch den Launcher-Service gestarteten Dienste werden beendet!
14. HF-Service-App (expert-hf-app)
14.1 Berechtigungskonfiguration
Für dieexpert-hf-app gibt es eine von APP verwaltete "Berechtigungskonfiguration", die beschreibt, auf welchen Hosts (z.B. TCLs) die App welche Aktionen durchführen kann. Wenn ein Host nicht explizit konfiguriert ist, ist nur Lesezugriff erlaubt.
Die entsprechende Informationsmeldung in der App sieht man im folgenden Screenshot. Eine Fehlermeldung im Logging gibt es offenbar bisher nicht.
 Eintrag neuer bzw. Entfernen obsoleter Berechtigungen erfolgt unter https://git.acc.gsi.de/fcc-applications/common-config/src/branch/pro/expert-hf-app.properties.
Eintrag neuer bzw. Entfernen obsoleter Berechtigungen erfolgt unter https://git.acc.gsi.de/fcc-applications/common-config/src/branch/pro/expert-hf-app.properties.
15. HowTo
15.1 Rollout
Falls eine neue SW-Version ausgerollt werden muss, ist das vorher mit dem Schichtleiter im HKR abzustimmen. Sollte ein Ausrollen bis zum nächsten Betriebsmeeting (Morning Briefing oder Mittagssitzung) nicht möglich sein, bitte im entsprechenden nächsten Betriebsmeeting vorbringen, damit ein geeigneter Zeitpunkt dafür festgelegt werden kann. Sollten dann immer noch nicht alle erreicht worden sein, die darüber Bescheid wissen müssten, werden diese per Email informiert.15.2 "Vollversorgung"
Eine "Vollversorgung" aus der Scheduling App heißt: Alle Patterns einer Pattern Group (oder sogar alle Patterns in allen Pattern Groups) ausplanen, versorgen ("Versorgen / Supply" oben rechts), gewünschte Patterns wieder einplanen, versorgen. Ob eine oder mehrere Pattern Groups betroffen sind, muss der RBler einschätzen (wenn z.B. 2 von 3 Pattern Groups fehlerfrei arbeiten, sollte man zunächst versuchen, nur die eine fehlerhafte neu zu versorgen, etc.). Eine "Vollversorgung" in Bezug auf Geräte / LSA-Settings findet aus ParamModi statt: Kontext auswählen, unten bei "An Geräte schicken" stattdessen über Dropdown "Ganzen Kontext schicken" wählen. Mehrere Kontexte ggf. nacheinander abarbeiten (kann z.B. notwendig sein, wenn ein Gerät neu zugeschaltet oder resettet wurde - dann müssen alle Kontexte, in denen dieses Gerät Settings haben kann, neu versorgt werden.)15.3 Diagnose bei OutOfMemory-Errors
Wenn bei einer Anwendung Fehlerverhalten auftritt (hängt, zeigt falsche Infos an, ...), bei dem man den Verdacht hat, dass ein vollgelaufener Speicher der Grund sein könnte oder man den Anwendungszustand genau analysieren möchte, dann kann ein Heapdump nützlich sein. Wenn möglich: Heapdump erzeugen und zukommen lassen. Falls das Problem im HKR auftrat und man selbst nicht vor Ort sein kann, je nach HKR-Besetzung die folgenden Schritte durchführen lassen.15.3.1 Prozess-ID ermitteln
Zum Beispiel durch eine der beiden Alternativen: Mit Hilfe von Logging-System (s.u.) oder durch den Operateur über das terminal auf der Konsole:jps und nach dem Programmnamen schauen. Beispiel:
jps 2529 DigitizerExpertApp 28707 Jps 486 LauncherAppBei der
DigitizerExpertApp wäre dies die PID 2529.
15.3.2 Heap Dump erstellen
jmap -dump:live,format=b,file=<filename>.hprof <PID>Zum Beispiel:
jmap -dump:live,format=b,file=/tmp/dump_digitizer_expert_app_tcl1030.hprof 2529
Dump auf den Cluster bringen (benötigt Cluster-Account):
scp /path/to/<dump-filename> <username>@asl75<n>:/tmp(n ist dabei die gewünschte asl Instanz. Bei dem Verzeichnis
/tmp muss auch auf der passenden asl nach der Datei geschaut werden. Statt /tmp kann auch z.B. /scratch/dump verwendet werden.)
Zum Beispiel: scp /tmp/dump_digitizer_expert_app_tcl1030.hprof awalter@asl754:/tmp
Es kann sein, dass noch der Dateizugriff durch den Operateur gewährt werden muss:
ssh <username>@asl75<n> chmod a+rw <filename>Die Dump-Datei dann bitte aus dem
/tmp oder /scratch Verzeichnis z.B. ins eigene Home-Verzeichnis umziehen, damit sie nicht automatisch gelöscht werden kann. Nach erfolgter Analyse kann die Datei dann gelöscht werden.
Analyse z.B. mit jvisualvm , Eclipse Memory Analyzer, …
15.3.3 Nachvollziehen der Fehler im Logging-System
Häufig werden OOMs von unserem Uncaught-Exception-Handler erwischt. Praktische Suchen sind z.B. (ggf. mit Einschränkung auf StackTrace-Feld):OutOfMemory
java.lang.OutOfMemoryError
StackTrace:*OutOfMemory
"heap space"
15.4. Diagnose hängender Anwendungen
Analog zum Heapdump kann ein Thread-Dump einen guten Überblick über den Stand der Anwendung geben. Ein Abzug kann mit folgendem Befehl gemacht werden.jstack PID > /tmp/thread-dump-example-app_tcl1030.txtPID Ermittlung und Dateitransfer wie oben in Abschnitt 11.3 zur „Diagnose bei OutOfMemory-Errors“.
Weiteres
OnCallDuty-Topics -- JuttaFitzek - 16 Aug 2017

{kind=link}
| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
2021-04-21_RDP-dev-test-vm.png | manage | 1 MB | 27 Apr 2021 - 09:03 | RaphaelMueller | RDP Config Example to Test Development Machine |
| |
whatsapp-app-instances.png | manage | 93 K | 10 Nov 2023 - 17:50 | ChristianHillbricht | |
| |
whatsapp-servers.png | manage | 95 K | 10 Nov 2023 - 17:52 | ChristianHillbricht | |
| |
who_you_gonna_call_diagram.graphml | manage | 105 K | 13 Jul 2023 - 15:36 | HannoHuether | |
| |
who_you_gonna_call_poster.odp | manage | 1 MB | 13 Jul 2023 - 15:34 | HannoHuether | |
| |
who_you_gonna_call_poster.pdf | manage | 388 K | 13 Jul 2023 - 14:59 | HannoHuether | |
| |
who_you_gonna_call_poster.svg | manage | 613 K | 13 Jul 2023 - 15:18 | HannoHuether |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r111 < r110 < r109 < r108 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r111 - 01 Feb 2024, AnnekeWalter
Ideas, requests, problems regarding Foswiki? Send feedback