|
|
You are here: Foswiki>Timing Web>TimingSystemDocumentation>TimingSystemDocuments>TimingSystemDocumentsReportsAndMeasurements>TimingSystemDocumentRep20180131 (15 Jan 2019, DietrichBeck)Edit Attach
Etherbone Performance Measurements
Introduction
Access to Wishbone (WB) slaves in the FPGA from the host system is a prominent use-case for the accelerator control system. For this report, the performance for Etherbone 'reads' is compared for different scenarios. The measurements were taken in early 2018 ("cherry release").Comparing Performance for Various Methods, Platforms and Bus Bridges
While Wishbone is the System-On-a-Chip (SoC) bus for communication between IP cores confined in the FPGA of a Timing Receiver, the EtherBone (EB) protocol is extends the reach of the SoC bus to remote FPGAs or processors, for an overview see here. Etherbone works most efficiently on modern serial buses such as PCIe, USB or Ethernet, but parallel buses like PCI or VME can be used too.Stack
 Figure: Stack from a user-space application to Wishbone (WB) slaves. The external hardware (not shown) is implemented by IP cores that have a Wishbone slave interface. Shown are a host system (top) and a SoC FPGA with Wishbone slaves (bottom).
The figure above shows the stack using the Etherbone (EB) protocol. From top to bottom: A user program in user-space uses the Etherbone API to configure a Etherbone cycle, that may include multiple 'reads' ('writes') from (to) the hardware The Etherbone library processes theses requests and hands them over to the Wishbone driver, which builds a EB frame (see here). The EB frame is passed on to the EB serial driver, which sends it over the (serial) bus to the FPGA. Here, the EB serial driver receives the frame and acts as Wishbone master to perform 32bit 'reads' and 'writes' on Wishbone SoC bus. If requested, the reply including the 'reads' is send up to stack and back to the user program.
Figure: Stack from a user-space application to Wishbone (WB) slaves. The external hardware (not shown) is implemented by IP cores that have a Wishbone slave interface. Shown are a host system (top) and a SoC FPGA with Wishbone slaves (bottom).
The figure above shows the stack using the Etherbone (EB) protocol. From top to bottom: A user program in user-space uses the Etherbone API to configure a Etherbone cycle, that may include multiple 'reads' ('writes') from (to) the hardware The Etherbone library processes theses requests and hands them over to the Wishbone driver, which builds a EB frame (see here). The EB frame is passed on to the EB serial driver, which sends it over the (serial) bus to the FPGA. Here, the EB serial driver receives the frame and acts as Wishbone master to perform 32bit 'reads' and 'writes' on Wishbone SoC bus. If requested, the reply including the 'reads' is send up to stack and back to the user program.
Methods
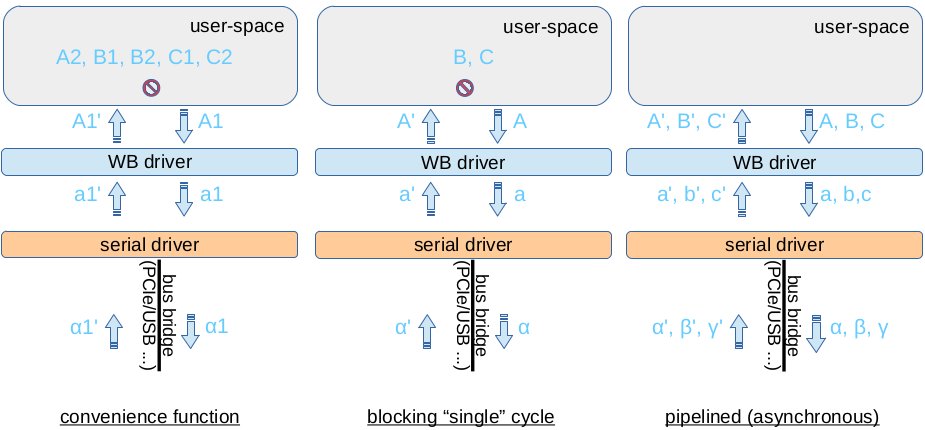 Figure: Three methods that can be used to communicate to the SoC via Etherbone. Shown are three requests (A, B and C), each with two read operations (A1, A2). Requests from the user program are marked by upper-case latin letters, Etherbone frames are marked by lower-case latin letters and the (serial) protocol of the bus bridge are marked by greek letters. Replies from the hardware are marked by an apostrophe.
As shown in the above figure, the following methods using Etherbone are provided by the API (from left to right).
Convenience Functions
These functions allow the to read (write) data from (to) Wishbone slaves with minute programming effort. They are easy to use, as the user does not need to program the EB cycles. As a downside, every operation (read or write) is encapsulated into a separate cycle. Convenience functions have the worst performance for multiple read (write) operation in terms of throughput and rate.
Blocking "Single" Cycles
Here, multiple reads and writes into the same EB cycle, which is configured as blocking. Performance-wise, all operations planned into the same EB cycle are processed at line speed. With today's high speed serial buses, the duration of one blocking EB cycle is dominated by the round trip time. Applications using blocking calls suffer, if multiple operations should be performed in a row: As shown in the figure, the request A (containing the two 'reads') is sent and the user program must wait for the reply from the hardware and the completion of the transaction, before the blocked cycle B (and later C ) can be committed. Still, blocking operation is inappropriate for applications requiring high throughput.
Pipelined (Asynchronous) Operation
Pipelined - asynchronous - operation allows processing multiple Etherbone cycles 'in flight' at the same time: Requests are 'streamed' from the host system to the hardware directly one after the other, while the host system receives the replies from the hardware asynchronously. As the serial bus is not blocked, full-duplexed serial buses can be utilized at line speed. Technically, the Etherbone API makes use of callback functions. In terms of "single cycle" round trip time, pipelined operation provides basically the same performance as blocking operation. In addition, it provides best performance for application requiring high data rates and/or throughput.
Figure: Three methods that can be used to communicate to the SoC via Etherbone. Shown are three requests (A, B and C), each with two read operations (A1, A2). Requests from the user program are marked by upper-case latin letters, Etherbone frames are marked by lower-case latin letters and the (serial) protocol of the bus bridge are marked by greek letters. Replies from the hardware are marked by an apostrophe.
As shown in the above figure, the following methods using Etherbone are provided by the API (from left to right).
Convenience Functions
These functions allow the to read (write) data from (to) Wishbone slaves with minute programming effort. They are easy to use, as the user does not need to program the EB cycles. As a downside, every operation (read or write) is encapsulated into a separate cycle. Convenience functions have the worst performance for multiple read (write) operation in terms of throughput and rate.
Blocking "Single" Cycles
Here, multiple reads and writes into the same EB cycle, which is configured as blocking. Performance-wise, all operations planned into the same EB cycle are processed at line speed. With today's high speed serial buses, the duration of one blocking EB cycle is dominated by the round trip time. Applications using blocking calls suffer, if multiple operations should be performed in a row: As shown in the figure, the request A (containing the two 'reads') is sent and the user program must wait for the reply from the hardware and the completion of the transaction, before the blocked cycle B (and later C ) can be committed. Still, blocking operation is inappropriate for applications requiring high throughput.
Pipelined (Asynchronous) Operation
Pipelined - asynchronous - operation allows processing multiple Etherbone cycles 'in flight' at the same time: Requests are 'streamed' from the host system to the hardware directly one after the other, while the host system receives the replies from the hardware asynchronously. As the serial bus is not blocked, full-duplexed serial buses can be utilized at line speed. Technically, the Etherbone API makes use of callback functions. In terms of "single cycle" round trip time, pipelined operation provides basically the same performance as blocking operation. In addition, it provides best performance for application requiring high data rates and/or throughput.
Measurement
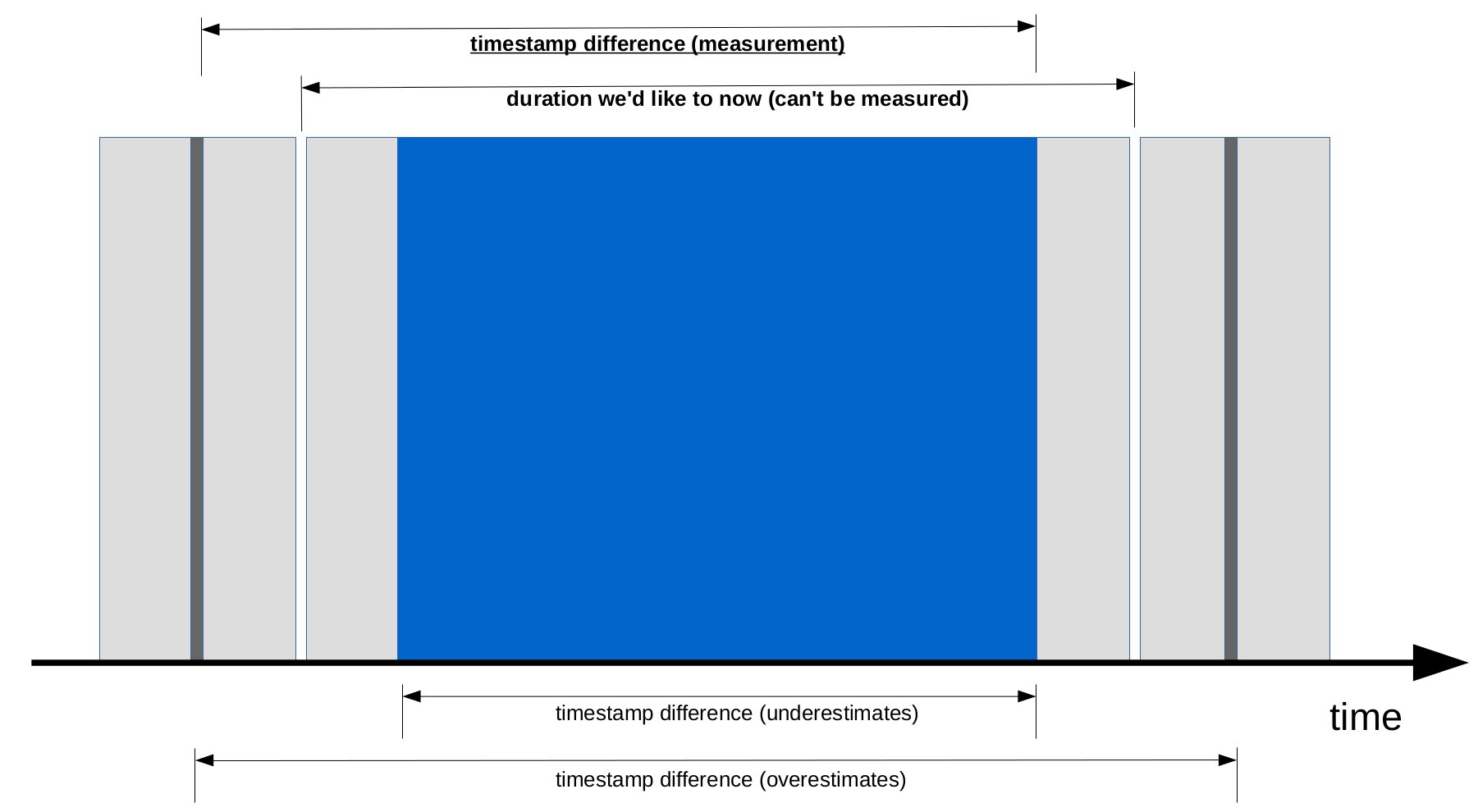 Figure: A Wishbone slave is used to obtain White Rabbit timetamps. Single timestamps are read in the FPGA from a Wishbone master (dark grey, left and right). In between, a series of timestamps is read from the same Wishbone master (dark blue, middle). The grey areas before/after the Wishbone read operations depict the overhead by the full stack from the user program to the Wishbone master. See text for description.
What we want to measure is the performance of Etherbone under various conditions. This includes the total time it takes to go through the full stack from user program to Wishbone slave and back. In this measurement, we have chosen the ECA as Wishbone slave providing 64bit White Rabbit timestamps. To start, we read a single timestamp from the ECA (dark grey, left). Then, we put a number of 'reads' into one Etherbone cycle and iterate a couple of times (middle, iterations not shown). Finally, we read a single concluding timestamp (dark grey, right). After the measurement, all(!) timestamps are available in the memory of the user program and can be analyzed. The figure above depicts a couple of possibilities to analyze the data.
Figure: A Wishbone slave is used to obtain White Rabbit timetamps. Single timestamps are read in the FPGA from a Wishbone master (dark grey, left and right). In between, a series of timestamps is read from the same Wishbone master (dark blue, middle). The grey areas before/after the Wishbone read operations depict the overhead by the full stack from the user program to the Wishbone master. See text for description.
What we want to measure is the performance of Etherbone under various conditions. This includes the total time it takes to go through the full stack from user program to Wishbone slave and back. In this measurement, we have chosen the ECA as Wishbone slave providing 64bit White Rabbit timestamps. To start, we read a single timestamp from the ECA (dark grey, left). Then, we put a number of 'reads' into one Etherbone cycle and iterate a couple of times (middle, iterations not shown). Finally, we read a single concluding timestamp (dark grey, right). After the measurement, all(!) timestamps are available in the memory of the user program and can be analyzed. The figure above depicts a couple of possibilities to analyze the data. - The time we are interested is the second topmost dimension line. Unfortunately, we cannot get this time span directly.
- Using first and last timestamp of all acquired data (dark blue in figure). This difference gives the time of Wishbone access, but does not include the overhead by the stack.
- Using the single timestamps measured before and after (dark grey). This difference includes the overhead of the stack twice.
- This is what is measured. Using the first single timestamp (left, dark grey) and the last measured timestamp of the series (dark blue, right). The difference - shown by the topmost dimension line - includes the full overhead of the stack only once.
- Remark: As we iterate over the full Etherbone cycle (middle, dark blue) many times, the difference between the observed times spans using the different measurement windows discussed above is only minor.
Data
Data and figures are available as attachment. Here, only a few graphs are shown. The following data are displayed for all figures.| Host and Serial Bus | color | method | symbol |
|---|---|---|---|
| SCU via PCIe | red | blocking | hourglass |
| SCU via PCIe | red | pipelined | arrow |
| SCU via GigE | yellow | blocking | hourglass |
| SCU via GigE | yellow | pipelined | arrow |
| Exploder via GigE | blue | blocking | hourglass |
| Exploder via GigE | blue | pipelined | arrow |
| Exploder via USB | green | blocking | hourglass |
| Exploder via USB | green | pipelined | arrow |
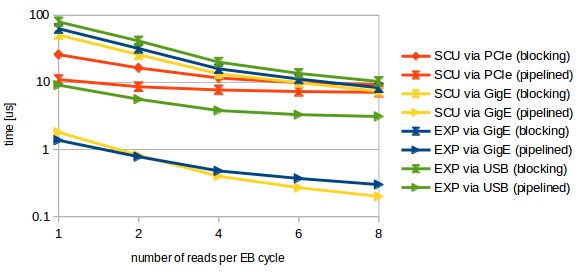 Figure: Time in microseconds it takes to read 8 bytes (64bit timestamp) from the ECA as a function of the number of timestamps per EB cycle. Note the logarithmic scale.
The above figure shows the time it takes to read 8 bytes. For blocking operation this time equals the round trip time of a single EB cycle. In contrast, the time required for processing 8 is reduced by pipelined (non-blocking) operation, when multiple cycles are sent in a row.
Figure: Time in microseconds it takes to read 8 bytes (64bit timestamp) from the ECA as a function of the number of timestamps per EB cycle. Note the logarithmic scale.
The above figure shows the time it takes to read 8 bytes. For blocking operation this time equals the round trip time of a single EB cycle. In contrast, the time required for processing 8 is reduced by pipelined (non-blocking) operation, when multiple cycles are sent in a row.
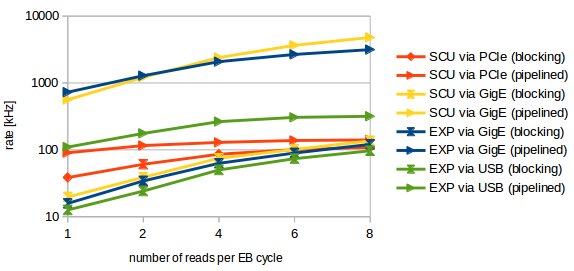 Figure: Rate in kilohertz that can be achieved when reading 8 bytes (64bit timestamp) from the ECA as a function of the number of timestamps per EB cycle. Note the logarithmic scale.
Figure: Rate in kilohertz that can be achieved when reading 8 bytes (64bit timestamp) from the ECA as a function of the number of timestamps per EB cycle. Note the logarithmic scale.
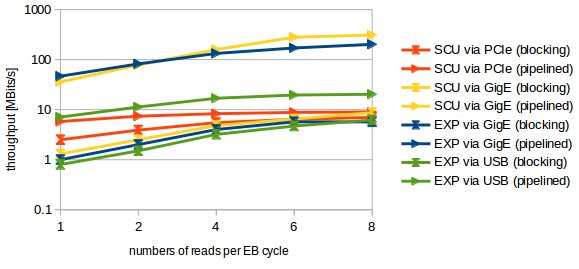 Figure: Throughput in Megabits per second that can be achieved when reading 8 bytes (64bit timestamp) from the ECA as a function of the number of timestamps per EB cycle. Note the logarithmic scale.
Figure: Throughput in Megabits per second that can be achieved when reading 8 bytes (64bit timestamp) from the ECA as a function of the number of timestamps per EB cycle. Note the logarithmic scale.
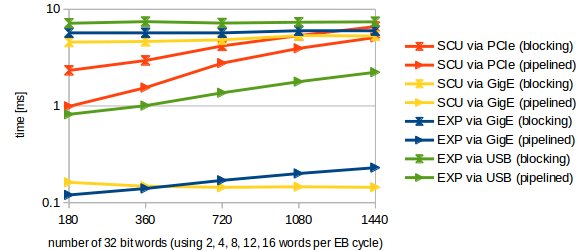 Figure: Time in milliseconds it takes to read words from the ECA as a function of the number of words. Note the logarithmic scale.
Figure: Time in milliseconds it takes to read words from the ECA as a function of the number of words. Note the logarithmic scale.
Result and Discussion
Blocking Operation via PCIe Looking at present performance of the SCU when using blocking calls via PCIe (red curves with hourglass), the following key data can be obtained for 64bit timestamps.- The time per timestamp (round tip time) is 25 us for one timestamp and drops below 10 us when reading multiple values within one Etherbone cycle.
- The rate than can be achieved is about 35kHz for one timestamp and increases to about 100kHz with multiple reads per cycle.
- The throughput increases from 2.5 MBit/s to about 7 MBit/s when using multiple reads.
- is not caused by using Etherbone,
- is not caused by the Wishbone SoC architecture,
- but only due to the PCIe driver presently used.
- SCU via pipelined PCIe: ~5970 ns per timestamp
- SCU via pipelined Gige: 64 ns per timestamp. This is
- 32 ns per Wishbone cycle (one 32bit word per cycle), or
- 4 FPGA clock cycles per Wishbone cycle.
Blocking Cycles: Performance 2018 versus 2014 values for TLU Reads
Here, the performance of reading timestamps from the Timestamp Latch Unit (TLU) is compared for present (2018) versus 2014Setup
A small command line program was run on the host system. Here, the Wishbone slave use as reference is the Timestamp Latch Unit (TLU). Blocking Etherbone cycles consisting of 3 reads (each 32bit) and 1 write (of 32 bit) were used.Data
| Bridge Type | Host System | OS | Cycle Time [us] | Rate [kHz] | Year |
|---|---|---|---|---|---|
| USB | Dell T3500 | 32bit GSI Debian | 134.0 | 7.5 | 2014 |
| USB | Dell T5810 | 64bit GSI Debian | 80.3 | 12.5 | 2018 |
| PCIe | Dell T3500 | 32bit GSI Debian | 8.3 | 120 | 2014 |
| PCIe | Dell T5810 | 64bit GSI Debian | 9.1 | 110 | 2018 |
| PCIe | SCU2 (32bit) | 32bit CentOS 6 | 27.4 | 36.5 | 2014 |
| PCIe | SCU3 (64bit) | 64bit CentOS 7 | 29.0 | 34.5 | 2018 |
| GigE [1] | SCU3 (64bit) | 64bit CentOS 7 | 50.4 | 19.8 | 2018 |
| VME (A32) | RIO4 | MBS | 16.5 | 60 | 2014 |
| VME (A32) | MEN A020 | 32bit CentOS 6 | 32.7 | 30.5 | 2014 |
Conclusion
- Etherbone works with high throughput and low latency when using with an appropriate driver via serial links.
- Etherbone works not very well for the present PCIe driver, as this driver is not capable of processing Wishbone 'reads' within one Etherbone cycle at line speed. An appropriate driver
- will clearly improve the performance for blocking cycles
- will dramatically improve the performance for pipelined operation
- When comparing the Etherbone performance for blocking calls, the performance is basically unchanged since a couple of years.


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
2018-02-01_ebPerformance.ods | manage | 93 K | 06 Feb 2018 - 18:16 | DietrichBeck | data and figures |
| |
etherboneArchitecture.jpg | manage | 121 K | 02 Feb 2018 - 15:07 | DietrichBeck | EB stack |
| |
etherboneMeasure.jpg | manage | 93 K | 02 Feb 2018 - 15:08 | DietrichBeck | |
| |
etherboneMethods.jpg | manage | 64 K | 04 Feb 2018 - 15:55 | DietrichBeck | EB methods |
| |
etherboneRateReading8Bytes.jpg | manage | 34 K | 06 Feb 2018 - 18:15 | DietrichBeck | rate reading 8 bytes from ECA |
| |
etherboneThroughputReading8Bytes.jpg | manage | 33 K | 06 Feb 2018 - 18:16 | DietrichBeck | throughput reading 8 bytes from ECA |
| |
etherboneTimeReading8Bytes.jpg | manage | 33 K | 06 Feb 2018 - 18:15 | DietrichBeck | time reading 8 bytes from ECA |
| |
etherboneTimeReadingNWords.jpg | manage | 35 K | 06 Feb 2018 - 18:16 | DietrichBeck | ime reading N 32bit words from ECA |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r9 < r8 < r7 < r6 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r9 - 15 Jan 2019, DietrichBeck
Ideas, requests, problems regarding Foswiki? Send feedback